
Java 集合框架 (java.util 包) 是 Java 语言中极其重要且实用的部分,几乎任何规模的程序都会用到它。掌握好集合是成为合格 Java 开发者的必经之路。
这份指南将系统性地带你学习 Java 集合的核心知识:
一、集合框架概述 (The Collections Framework)
为什么需要集合?
数组(
Array)的局限性:长度固定、类型单一、缺乏现成的操作方法(如查找、插入、删除等)。集合(
Collection):用于动态存储和操作一组对象。长度可变、类型更灵活(通过泛型)、提供了丰富的操作 API。
框架的核心设计思想:接口与实现分离
接口 (
Interface): 定义集合的行为规范(有哪些操作方法)。这是你编程时应该主要依赖的部分。实现 (
Implementation): 提供接口的具体实现类。选择不同的实现类取决于你的具体需求(性能、线程安全、排序等)。算法 (
Algorithms):Collections工具类提供了很多作用于集合的静态通用算法(排序、搜索、洗牌、求极值等),这些算法可以应用于不同的实现。
核心接口层次结构
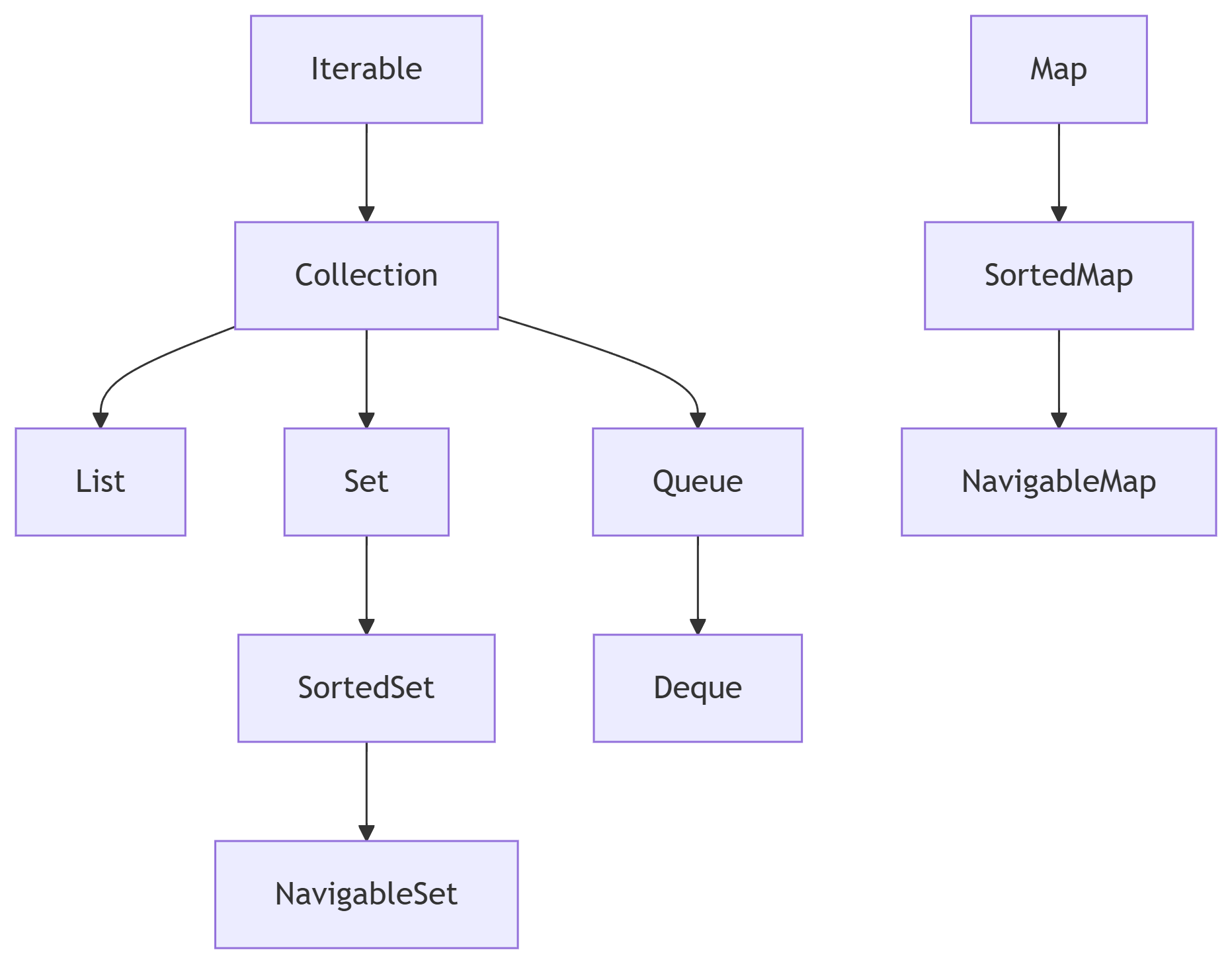
Iterable: 所有集合的顶级接口。实现此接口的对象支持for-each循环。核心方法是iterator()。Collection: 单列数据集合的根接口。定义了最通用的集合操作(添加、删除、包含、大小、遍历等)。List: 有序、可重复 的集合。用户可以对列表中每个元素的插入位置进行精确控制,可以根据整数索引访问元素。像动态数组。Set: 无序、不可重复 的集合。不允许包含重复元素。像数学中的集合。SortedSet: 继承Set,元素自动排序。NavigableSet: 继承SortedSet,提供了更丰富的导航方法(如查找最接近的元素)。
Queue: 队列。通常(但不一定)是 FIFO(先进先出)的集合。用于在处理前保存元素。Deque: 双端队列。允许在队列的两端插入和移除元素。可以当作栈或队列使用。
Map: 双列数据集合,保存键值对 (Key-Value) 映射。Key是唯一的。SortedMap: 继承Map,按键自动排序。NavigableMap: 继承SortedMap,提供了更丰富的导航方法。
二、核心接口详解与常用实现类
List接口 (有序、可重复)特点:元素有顺序(索引)、可重复、允许
null。核心实现类:
ArrayList:底层:动态数组。
优点:随机访问 (
get(index),set(index)) 速度极快 (O(1)时间复杂度)。缺点:在列表中间插入(
add(index))或删除(remove(index))元素相对较慢(需要移动后续元素,O(n))。适用场景:查询操作多、增删操作主要在尾部的情况。最常用。
LinkedList:底层:双向链表。
优点:在列表任何位置进行插入和删除操作都非常快 (
O(1),前提是已知位置)。实现了Deque接口,可用作栈、队列或双端队列。缺点:随机访问慢 (
O(n),需要从头或尾遍历)。占用内存比ArrayList稍多(存储前后节点引用)。适用场景:需要频繁在任意位置插入删除元素,或者需要栈、队列功能。
Vector:古老的实现类(JDK 1.0),线程安全(方法用
synchronized修饰)。缺点:性能通常比
ArrayList差(同步开销)。不推荐在新代码中使用。它的一个子类Stack(栈) 也因设计问题而不推荐,用Deque代替(如ArrayDeque)。
CopyOnWriteArrayList(在java.util.concurrent包):线程安全的变体。任何修改操作(
add,set,remove)都会创建底层数组的新副本。读操作不加锁,非常快。适用场景:读操作远远多于写操作,且需要保证线程安全的场景(如事件监听器列表)。写操作开销大(复制整个数组)。
Set接口 (无序、唯一)特点:元素唯一(不允许重复)、大多数实现类无序(
LinkedHashSet和SortedSet实现类除外)、允许null(通常最多一个)。判断元素唯一性的标准:
equals()和hashCode()方法!放入Set的类必须正确重写这两个方法。核心实现类:
HashSet:底层:基于
HashMap实现(实际上是将元素作为HashMap的Key存储)。特点:无序(遍历顺序不保证与插入顺序一致)、查询速度最快(理想情况下
O(1))、最常用。实现原理:通过计算元素的
hashCode()值决定存储位置,通过equals()比较是否重复。
LinkedHashSet:继承
HashSet。底层:基于
LinkedHashMap实现。特点:在
HashSet基础上,额外维护了一个双向链表。遍历顺序与元素插入顺序一致。查询速度略低于HashSet(维护链表开销),插入性能略受影响。适用场景:既需要集合的唯一性,又需要维护插入顺序。
TreeSet:底层:基于
TreeMap实现(红黑树)。特点:元素自动排序(实现了
SortedSet/NavigableSet)。排序方式有两种:自然排序 (
Comparable): 元素类必须实现Comparable接口并定义compareTo()方法。定制排序 (
Comparator): 创建TreeSet时传入一个Comparator对象来指定排序规则。
优点:有序,提供了丰富的导航方法(
first(),last(),higher(),lower()等)。缺点:插入和删除操作相对较慢(需要维护树的平衡,
O(log n)),查询也基于树查找 (O(log n))。适用场景:需要元素自动排序或需要基于范围进行高效操作。
CopyOnWriteArraySet(在java.util.concurrent包):线程安全,基于
CopyOnWriteArrayList。特点:类似
CopyOnWriteArrayList,适用于读多写少的线程安全场景。性能在元素多时较差(检查唯一性需要遍历)。
EnumSet:专为枚举类型设计的
Set实现。特点:内部用位向量实现,非常高效、紧凑。所有元素必须来自同一个枚举类型。
适用场景:存储枚举常量集合。
Queue接口 (队列) &Deque接口 (双端队列)Queue核心方法:offer(e): 添加元素到队尾(推荐使用,失败返回false)。poll(): 移除并返回队头元素(队列为空时返回null)。peek(): 获取(不移除)队头元素(队列为空时返回null)。add(e)/remove()/element(): 类似上面三个,但操作失败时抛出异常(不推荐)。
Deque核心方法 (扩展Queue):两端操作:
offerFirst(e)/offerLast(e),pollFirst()/pollLast(),peekFirst()/peekLast()。可以用作栈:
push(e)(等价于addFirst(e)),pop()(等价于removeFirst()),peek()(等价于peekFirst())。
核心实现类:
LinkedList: 同时实现了List和Deque。可用作队列、双端队列、栈。基于链表实现,插入删除快,随机访问慢。ArrayDeque:底层:动态数组(循环数组)。
特点:作为栈和队列使用时性能通常优于
LinkedList(内存更连续)。不允许null元素。适用场景:需要栈或队列功能时的首选实现(单线程环境)。
PriorityQueue:底层:堆(通常是最小堆)。
特点:优先级队列。元素出队顺序不是 FIFO,而是根据优先级(自然排序或
Comparator),每次出队的是优先级最高(或最低)的元素。适用场景:任务调度、求 Top K 问题等需要按优先级处理元素的场景。
阻塞队列 (
BlockingQueue接口及其实现,在java.util.concurrent包):线程安全的队列,当队列满时添加操作会阻塞,队列空时获取操作会阻塞。
核心实现:
ArrayBlockingQueue,LinkedBlockingQueue,PriorityBlockingQueue,SynchronousQueue,DelayQueue等。是并发编程的重要工具。
Map接口 (键值对)特点:存储
Key-Value映射。Key唯一,Value可重复。判断 Key 唯一性的标准:
equals()和hashCode()方法!用作Key的类必须正确重写这两个方法。核心实现类:
HashMap:底层:数组 + 链表/红黑树(JDK 8 引入红黑树优化长链表性能)。
特点:无序(遍历顺序不保证)、基于 Key 的哈希值存取,查询速度最快(理想情况下
O(1))、允许null作为 Key 和 Value、最常用。重要参数:
initialCapacity: 初始数组大小(默认16)。loadFactor: 负载因子(默认0.75),决定何时扩容(size >= capacity * loadFactor)。threshold: 扩容阈值 (capacity * loadFactor)。
扩容 (
resize()): 当达到阈值时,创建一个新数组(通常是原容量的2倍),重新计算所有键的哈希值并分配到新数组的桶中(rehash)。开销较大。
LinkedHashMap:继承
HashMap。底层:在
HashMap基础上额外维护了一个双向链表(记录插入顺序或访问顺序)。特点:
遍历顺序可以是插入顺序或访问顺序(LRU - Least Recently Used 最近最少使用)。
通过构造函数参数
accessOrder(true表示访问顺序,false表示插入顺序) 控制。查询速度略低于
HashMap(维护链表开销)。
适用场景:需要维护插入顺序或实现简单的 LRU 缓存。
TreeMap:底层:红黑树。
特点:按键自动排序(实现了
SortedMap/NavigableMap)。排序规则同样通过Comparable或Comparator定义。优点:有序,提供了丰富的导航方法(
firstKey(),lastKey(),higherKey(),lowerKey()等)。缺点:插入、删除、查询操作基于树结构 (
O(log n)),比HashMap慢。适用场景:需要按键排序或需要基于键的范围进行高效操作。
Hashtable:古老的实现类(JDK 1.0),线程安全(方法用
synchronized修饰)。缺点:性能通常比
HashMap差(同步开销)。不允许null作为 Key 或 Value。不推荐在新代码中使用。
ConcurrentHashMap(在java.util.concurrent包):线程安全的高性能
Map实现。推荐在多线程环境下替代HashMap和Hashtable。特点:
JDK 7 采用分段锁机制。
JDK 8 及以后采用
synchronized+CAS+ 红黑树,锁粒度更细(锁单个桶/链表/树节点)。提供高并发读写性能。迭代器是弱一致性的(不保证反映所有最新修改)。
Properties:继承自
Hashtable。特点:主要用于处理
.properties配置文件。Key和Value都是String类型。提供了方便的load()/store()方法读写流。
WeakHashMap:特点:
Key是弱引用。当某个Key不再被外部强引用或软引用指向时,该键值对会被垃圾回收器自动回收。适用场景:实现缓存(当内存不足时自动清理),或需要关联对象生命周期的情况。
三、关键概念与技巧
泛型 (
Generics)核心作用:类型安全(编译时检查类型错误)和 消除强制类型转换。
用法:在声明集合变量和创建集合对象时指定元素类型。
List<String> names = new ArrayList<>(); // 存储String的List Map<Integer, Student> studentMap = new HashMap<>(); // Key为Integer, Value为Student的Map通配符 (
?):<? extends T>(上界),<? super T>(下界),<?>(无界)。用于更灵活地处理泛型集合的传递。理解 PECS 原则 (Producer-Extends, Consumer-Super)。
遍历集合 (
Iteration)for-each循环 (推荐):简洁,底层使用Iterator。for (String name : names) { System.out.println(name); }Iterator迭代器:更底层,可以在遍历时安全地移除元素 (remove()方法)。Iterator<String> it = names.iterator(); while (it.hasNext()) { String name = it.next(); if (someCondition) { it.remove(); // 安全删除当前元素 } }ListIterator:List专用迭代器,支持双向遍历和修改(add(),set())。forEach()方法 (Java 8+): 结合 Lambda 表达式。names.forEach(name -> System.out.println(name)); // 或 names.forEach(System.out::println);遍历
Map:// 遍历所有Key for (Integer id : studentMap.keySet()) { ... } // 遍历所有Value for (Student student : studentMap.values()) { ... } // 遍历所有Entry (Key-Value对) - 最常用 for (Map.Entry<Integer, Student> entry : studentMap.entrySet()) { Integer id = entry.getKey(); Student student = entry.getValue(); ... } // Java 8+ forEach studentMap.forEach((id, student) -> System.out.println(id + ": " + student));
Collections工具类提供大量静态方法用于操作或返回集合(排序、搜索、替换、同步包装、不可变包装等)。
常用方法:
sort(list),sort(list, comparator): 排序。binarySearch(list, key): 二分查找(列表必须先排序)。reverse(list),shuffle(list),rotate(list, distance),swap(list, i, j): 反转、洗牌、旋转、交换元素。max(collection),min(collection): 求最大/最小值。frequency(collection, obj): 元素出现频率。synchronizedXxx(collection): 返回指定集合的线程安全(同步)包装版本(如synchronizedList,synchronizedMap)。性能不如ConcurrentHashMap等并发集合,使用时要手动同步对迭代器的访问。unmodifiableXxx(collection): 返回指定集合的不可修改视图(只读)。emptyXxx(),singleton(),singletonList(),singletonMap(): 返回空集合或单元素集合。addAll(collection, elements...): 添加多个元素。copy(dest, src): 复制列表。disjoint(collection1, collection2): 检查两个集合是否不相交(无共同元素)。replaceAll(list, oldVal, newVal): 替换所有匹配元素。
Arrays工具类提供操作数组的静态方法,包括
asList(T... a),它可以将数组转换为一个固定大小的List视图(对返回List的结构修改会抛出异常UnsupportedOperationException,但可以修改元素值)。
正确重写
equals()和hashCode()equals()规则:自反性、对称性、传递性、一致性、非空性 (x.equals(null) == false)。hashCode()规则:如果两个对象
equals()比较相等,那么它们的hashCode()值必须相等。如果两个对象
equals()比较不相等,它们的hashCode()值尽量不相等(但允许相等,即哈希冲突)。
为什么必须同时重写? 当对象作为
HashMap/HashSet的Key时,hashCode()决定桶位置,equals()解决桶内冲突。如果只重写一个,会破坏集合的正确性(比如两个equals相等的对象可能被放在不同的桶里)。
ComparablevsComparatorComparable(自然排序):接口,类实现它 (
class MyClass implements Comparable<MyClass>)。定义类的默认排序规则 (
int compareTo(MyClass o)方法)。
Comparator(定制排序):接口,单独定义比较器 (
class MyComparator implements Comparator<MyClass>)。提供灵活的、多种排序规则 (
int compare(MyClass o1, MyClass o2)方法)。可以在创建有序集合 (
TreeSet,TreeMap) 或调用排序方法 (Collections.sort(),Arrays.sort()) 时传入。
Lambda 表达式简化
Comparator(Java 8+):Collections.sort(students, (s1, s2) -> s1.getAge() - s2.getAge()); // 或更简洁 Collections.sort(students, Comparator.comparingInt(Student::getAge));
选择哪个集合实现?
考虑因素:
元素是否唯一? -> 唯一用
Set/Map,不唯一用List。是否需要顺序?
插入顺序:
LinkedList,LinkedHashSet,LinkedHashMap。自然/定制排序:
TreeSet,TreeMap。索引访问:
ArrayList,LinkedList(后者慢)。
主要操作是什么?
随机访问 (
get(index)/get(key)):ArrayList/HashMap/LinkedHashMap。频繁插入删除:
LinkedList(任意位置),ArrayList(尾部还行)。频繁检查存在性 (
contains()):HashSet/HashMap。
是否线程安全? -> 单线程用普通集合 (
ArrayList,HashMap), 多线程用java.util.concurrent包下的并发集合 (ConcurrentHashMap,CopyOnWriteArrayList) 或用Collections.synchronizedXxx()包装(注意迭代器问题)。是否需要键值对? -> 是
Map,否Collection(List/Set/Queue)。是否需要队列/栈功能? ->
Queue/Deque(LinkedList,ArrayDeque,PriorityQueue)。
性能考虑 (
Big-O)理解常用操作(
add,remove,contains,get)在不同集合实现上的时间复杂度至关重要。选择错误的集合会导致性能瓶颈。典型时间复杂度:
Java 8+ 对集合的增强 (Stream API)
Stream不是集合,而是一种对集合进行高效批量数据操作(过滤、映射、排序、聚合等)的 API。提供声明式、函数式风格的编程。
核心操作:
filter,map,flatMap,distinct,sorted,peek,limit,skip,forEach,collect,reduce,count,anyMatch/allMatch/noneMatch,findFirst/findAny等。示例:
List<String> longNames = names.stream() .filter(name -> name.length() > 5) // 过滤 .map(String::toUpperCase) // 映射 (转换) .sorted() // 排序 .collect(Collectors.toList()); // 收集结果
四、最佳实践与常见陷阱
优先使用接口类型声明集合变量:
List<String> list = new ArrayList<>(); // 好 ArrayList<String> list = new ArrayList<>(); // 不够灵活 (特定实现)预估大小,避免频繁扩容:创建
ArrayList/HashMap等时,如果知道大致容量,使用带初始容量的构造函数 (new ArrayList<>(100),new HashMap<>(256, 0.75f))。尤其对于HashMap,减少rehash次数。Map的Key类型选择:选择不可变类(如String,Integer, 自定义的不可变类)作为Key。如果Key可变且其hashCode()依赖的属性改变,会导致在Map中无法定位到该键值对,造成内存泄漏和逻辑错误。不要在遍历集合时直接删除元素 (非
Iterator.remove()):使用for-each循环或普通的for循环遍历List时直接调用remove()会抛出ConcurrentModificationException。应使用Iterator.remove()。并发修改问题也存在于Map的遍历中。理解
ConcurrentModificationException:当使用迭代器遍历集合时,如果集合本身(非通过该迭代器的remove()方法)被修改(添加、删除元素),就会抛出此异常。这是快速失败 (fail-fast) 机制。线程安全的选择:
单线程环境:普通集合 (
ArrayList,HashMap)。高并发读多写少:
CopyOnWriteArrayList,CopyOnWriteArraySet。高并发读写:
ConcurrentHashMap(首选),ConcurrentSkipListMap/ConcurrentSkipListSet(需要排序时)。阻塞队列:
ArrayBlockingQueue,LinkedBlockingQueue等。慎用
Collections.synchronizedXxx():它只保证单个方法调用是原子的,但复合操作(如if (!map.containsKey(key)) map.put(key, value))仍需外部同步,且迭代器访问也需要手动同步。性能通常不如专门的并发集合。
使用
isEmpty()判断是否为空:不要用size() == 0。Arrays.asList()返回的是固定大小列表:不能add/remove。List.of(),Set.of(),Map.of()(Java 9+):创建不可变集合。不能添加、删除、修改元素(UnsupportedOperationException)。性能好,安全。为集合元素选择合适的类:确保放入集合的类正确实现了
equals(),hashCode()(用于基于哈希的集合和作为Map的Key),以及Comparable(如果需要自然排序)。
学习路径建议
打好基础:彻底理解
List,Set,Map三大核心接口及其最常用实现 (ArrayList,LinkedList,HashSet,LinkedHashSet,HashMap,LinkedHashMap) 的特点、用法和区别。掌握遍历与工具类:熟练使用
for-each,Iterator和各种Collections/Arrays工具方法。深入
equals/hashCode/Comparable/Comparator:这是集合正确工作的基石。理解性能:记住常用操作的时间复杂度,根据场景选择最优集合。
学习并发集合:掌握
ConcurrentHashMap,CopyOnWriteArrayList等在多线程环境下的使用。探索高级特性:学习
Queue/Deque(ArrayDeque,PriorityQueue),TreeSet/TreeMap,WeakHashMap等特定场景下有用的集合。拥抱 Stream API:学习 Java 8+ 的 Stream 进行高效数据处理。
实践、实践、再实践!多做练习,解决实际问题,是掌握集合的最佳途径。
Java 集合框架博大精深,但只要你循序渐进,理解核心概念和设计思想,勤加练习,一定能运用自如。祝你学习顺利!